Die Ausgangssituation
Dutzende Streamlit-Anwendungen in verschiedenen Umgebungen, unterschiedliche Python-Versionen, inkonsistente Sicherheitspraktiken beim Zugriff auf sensible Daten. Manche Anwendungen funktionieren, andere versagen ohne nachvollziehbaren Grund. Niemand weiß, wer welche Anwendung erstellt hat oder wie sie zu warten ist.
Genau vor dieser Situation stand unser Data Team. Anwendungen entstanden isoliert, ohne Standardisierung, ohne Security-Oversight, ohne klaren Deployment-Prozess. Das Ergebnis: ein Compliance-Risiko und eine Wartungslast, die exponentiell wuchs.
Für Unternehmen mit regulatorischen Anforderungen (DSGVO, Branchenstandards) stellt diese dezentrale Infrastruktur ein systematisches Governance-Problem dar. Audit-Trails fehlen, Zugriffskontrollen sind inkonsistent, und nachträgliche Compliance-Implementierung verursacht erhebliche Kosten. Der hier beschriebene Ansatz zeigt, wie frühe Governance-Implementierung diese Risiken vermeidet.
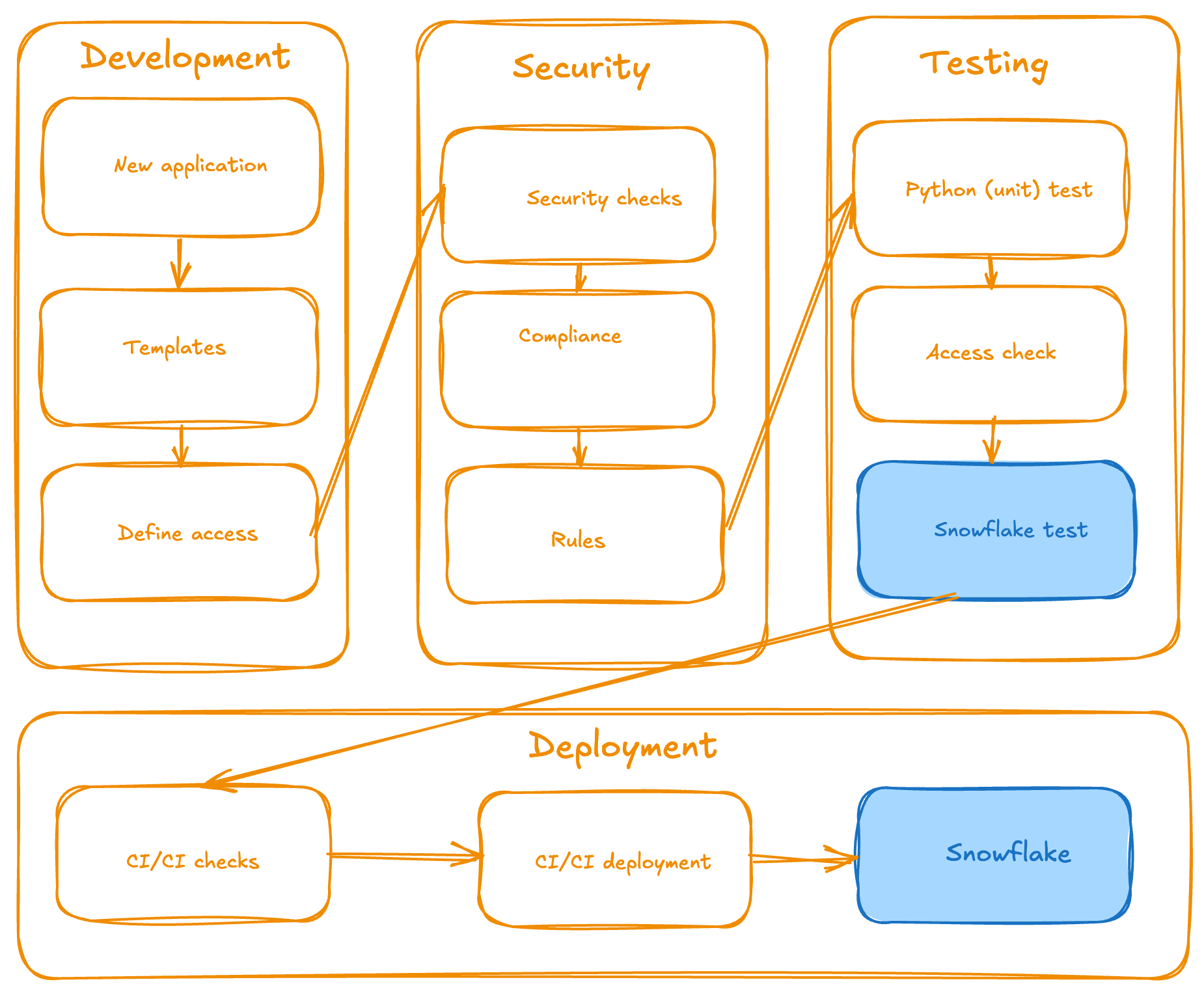
<p></p>
<center><i>Funktionale Architektur (High-Level-Übersicht)</i></center>
Der methodische Ansatz
Als "Customer Zero" haben wir das gesamte Framework auf GitLabs eigener CI/CD-Infrastruktur und den Projekt-Management-Tools aufgebaut. Die Grundkomponenten:
-
GitLab (Produkt)
-
Snowflake – Single Source of Truth (SSOT) für Data-Warehouse-Aktivitäten
-
Streamlit – Open-Source-Tool für visuelle Anwendungen mit Python-Code
Dies ermöglichte direkten Zugriff auf Enterprise-DevSecOps-Funktionen: automatisierte Tests, Code-Review-Prozesse und Deployment-Pipelines von Beginn an. Durch GitLabs integrierte Features für Issue-Tracking, Merge-Requests und automatisierte Deployments (CI/CD-Pipelines) konnten wir schnell iterieren und das Framework gegen reale Enterprise-Anforderungen validieren. Dieser Internal-First-Ansatz stellte sicher, dass die Lösung im Produktiveinsatz bei GitLab selbst validiert wurde.
Erkenntnisse aus der Implementierung
Die wichtigste Erkenntnis beim Aufbau des Streamlit Application Framework in Snowflake: Struktur schlägt Chaos systematisch – Governance früh implementieren, nicht nachträglich, wenn die Wartungskosten exponentiell steigen.
Rollen und Verantwortlichkeiten müssen klar definiert sein. Infrastruktur-Concerns werden von Application Development getrennt, sodass jedes Team sich auf seine Stärken konzentrieren kann.
Security und Compliance können keine Nachgedanken sein. Sie müssen von Tag eins in Templates und automatisierte Prozesse integriert werden. Konsistente Standards vorab durchzusetzen ist wesentlich effizienter als nachträgliche Implementierung. Investitionen in Automatisierung und CI/CD-Pipelines zahlen sich aus, da manuelle Prozesse nicht skalieren und menschliche Fehler einführen.
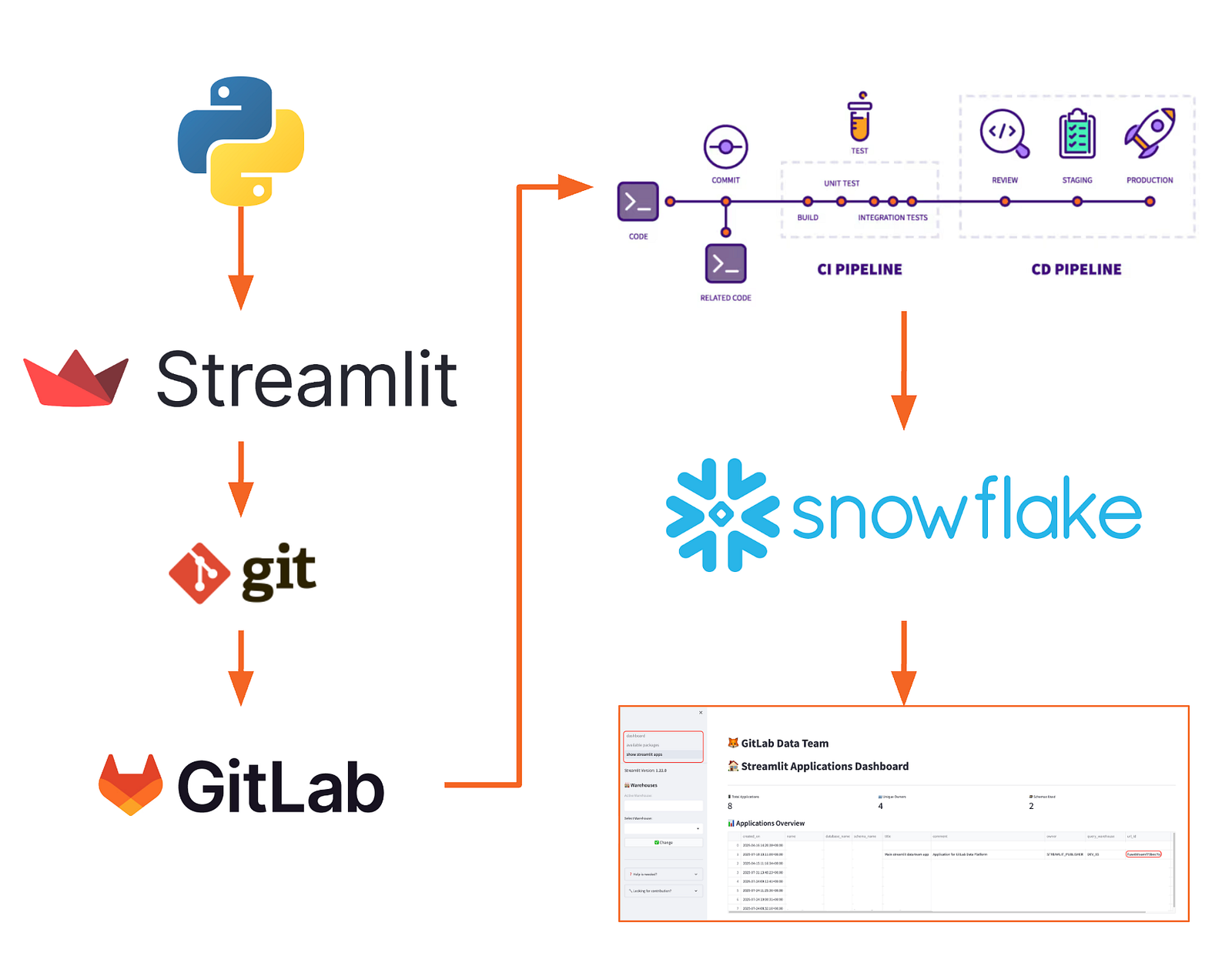
<p></p>
<center><i>Framework-Architektur (Gesamtübersicht)</i></center>
Das Streamlit Application Framework
Das Framework verwandelt dezentrale Ansätze in eine strukturierte Lösung. Entwicklungsteams erhalten Freiheit innerhalb sicherer Leitplanken, während Deployment automatisiert und Wartungskomplexität eliminiert wird.
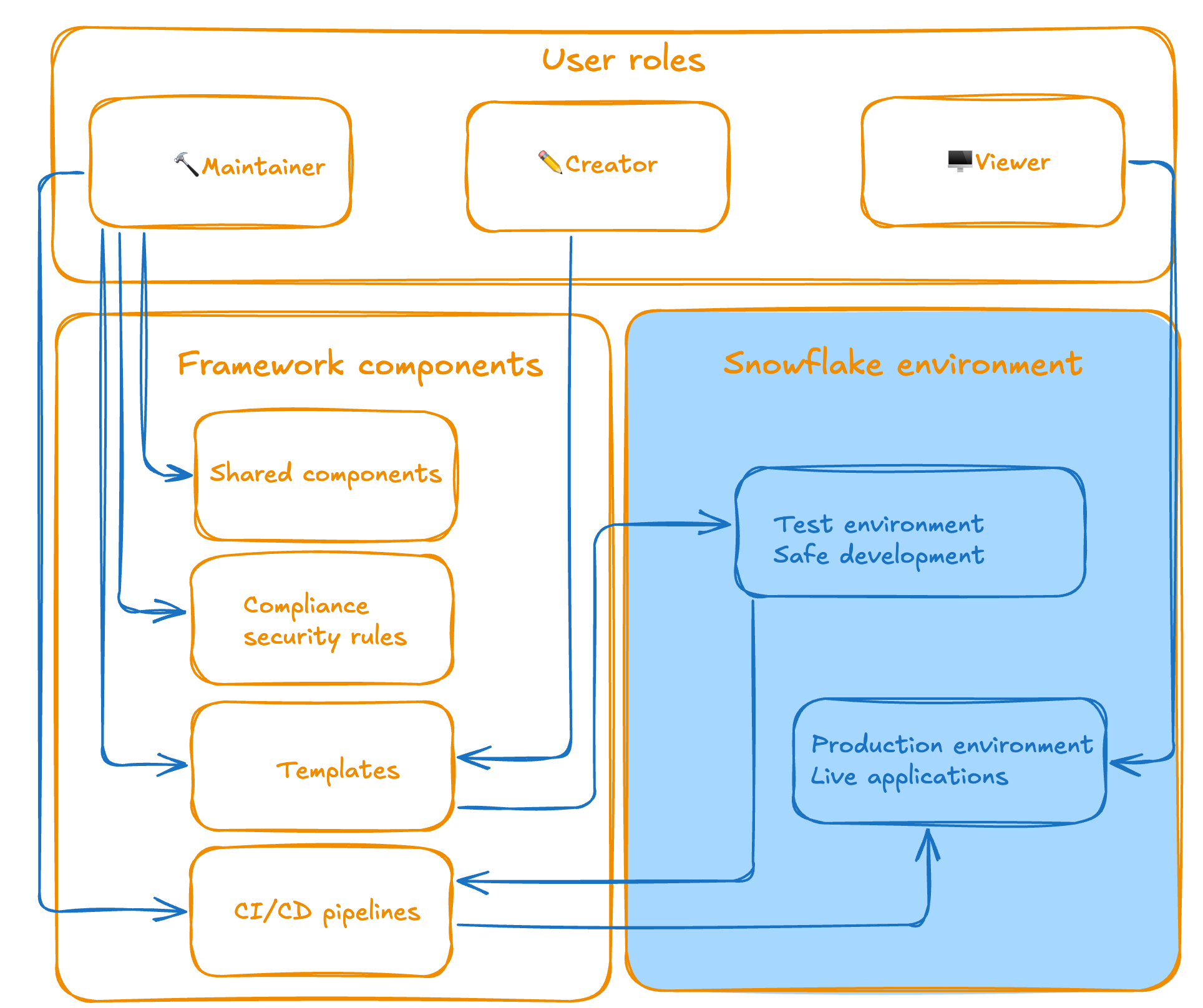
Drei Rollen, ein einheitlicher Prozess
Das Framework führt einen strukturierten Ansatz mit drei klar getrennten Rollen ein:
-
Maintainers (Data-Team-Mitglieder und Contributors) verwalten die Infrastruktur: CI/CD-Pipelines, Security-Templates und Compliance-Regeln. Sie stellen sicher, dass das Framework funktioniert und sicher bleibt.
-
Creators (Anwendungsentwicklungsteams) konzentrieren sich auf ihre Kernkompetenzen: Visualisierungen erstellen, Snowflake-Daten einbinden, User Experiences gestalten. Volle Flexibilität beim Erstellen neuer Anwendungen von Grund auf, beim Hinzufügen neuer Pages zu bestehenden Apps, beim Integrieren zusätzlicher Python-Libraries und beim Bauen komplexer Datenvisualisierungen, ohne Beschäftigung mit Deployment-Pipelines oder Security-Konfigurationen.
-
Viewers (Endnutzer) greifen auf fertige, sichere Anwendungen zu, ohne technischen Overhead. Benötigt wird lediglich Snowflake-Zugriff.
<p></p>
<center><i>Rollen-Übersicht und ihre Funktionen</i></center>
Vollständige Automatisierung
Durch CI/CD-Implementierung gehören tagelange manuelle Deployments und Konfigurationsaufwand der Vergangenheit an. Das Framework bietet:
- Umgebungsvorbereitung per Kommando: Mit
make-Befehlen ist die Umgebung in wenigen Sekunden installiert und einsatzbereit.
================================================================================
✅ Snowflake CLI successfully installed and configured!
Connection: gitlab_streamlit
User: YOU@GITLAB.COM
Account: gitlab
================================================================================
Using virtualenv: /Users/YOU/repos/streamlit/.venv
📚 Installing project dependencies...
Installing dependencies from lock file
No dependencies to install or update
✅ Streamlit environment prepared!
-
Automatisierte CI/CD-Pipelines: Übernehmen Testing, Code-Review und Deployment von Development bis Production.
-
Sichere Sandbox-Umgebungen: Ermöglichen sichere Entwicklung und Tests vor Production-Deployment.
╰─$ make streamlit-rules
🔍 Running Streamlit compliance check...
================================================================================
CODE COMPLIANCE REPORT
================================================================================
Generated: 2025-07-09 14:01:16
Files checked: 1
SUMMARY:
✅ Passed: 1
❌ Failed: 0
Success Rate: 100.0%
APPLICATION COMPLIANCE SUMMARY:
📱 Total Applications Checked: 1
⚠️ Applications with Issues: 0
📊 File Compliance Rate: 100.0%
DETAILED RESULTS BY APPLICATION:
...
- Template-basierte Anwendungserstellung: Gewährleistet Konsistenz über alle Anwendungen und Pages hinweg.
╰─$ make streamlit-new-page STREAMLIT_APP=sales_dashboard STREAMLIT_PAGE_NAME=analytics
📝 Generating new Streamlit page: analytics for app: sales_dashboard
📃 Create new page from template:
Page name: analytics
App directory: sales_dashboard
Template path: page_template.py
✅ Successfully created 'analytics.py' in 'sales_dashboard' directory from template
-
Poetry-basiertes Dependency-Management: Verhindert Versionskonflikte und erhält saubere Umgebungen.
-
Organisierte Projektstruktur: Dedizierte Ordner für Anwendungen, Templates, Compliance-Regeln und Configuration-Management.
├── src/
│ ├── applications/ # Ordner für Streamlit-Anwendungen
│ │ ├── main_app/ # Main-Dashboard-Anwendung
│ │ ├── components/ # Gemeinsam genutzte Komponenten
│ │ └── <your_apps>/ # Eigene Anwendungen
│ │ └── <your_apps2>/ # Weitere Anwendungen
│ ├── templates/ # Anwendungs- und Page-Templates
│ ├── compliance/ # Compliance-Regeln und -Checks
│ └── setup/ # Setup- und Konfigurations-Utilities
├── tests/ # Test-Dateien
├── config.yml # Umgebungskonfiguration
├── Makefile # Build- und Deployment-Automatisierung
└── README.md # Haupt-README-Datei
- Optimierter Workflow: Von lokaler Entwicklung über Test-Schema bis Production, vollständig automatisiert durch GitLab CI/CD-Pipelines.
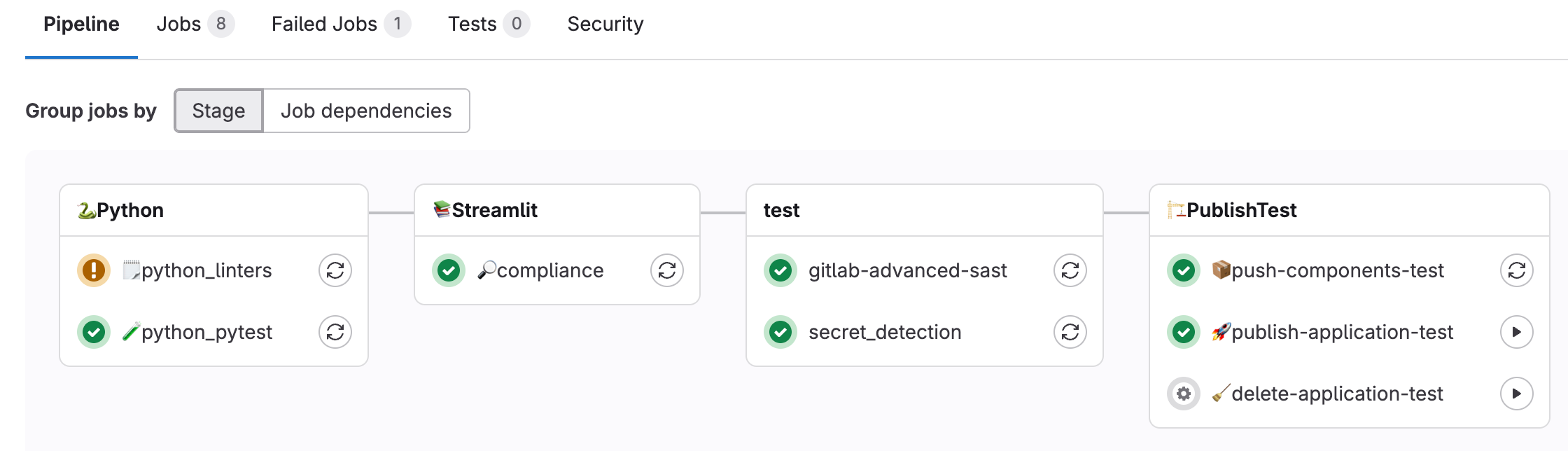
<p></p> <center><i>GitLab CI/CD-Pipelines für vollständige Prozessautomatisierung</i></center>
Security und Compliance by Design
Statt Security nachträglich hinzuzufügen, baut das Streamlit Application Framework sie von Grund auf ein. Jede Anwendung folgt denselben Security-Standards, Compliance-Anforderungen werden automatisch durchgesetzt. Audit-Trails werden über den gesamten Development-Lifecycle gepflegt.
Compliance-Regeln werden mit einem einzigen Kommando eingeführt und verifiziert. Beispielsweise lassen sich definieren, welche Klassen und Methoden verpflichtend sind, welche Dateien vorhanden sein müssen und welche Rollen für das Teilen der Anwendung erlaubt oder verboten sind. Die Regeln sind flexibel und beschreibend – Definition erfolgt in einer YAML-Datei:
class_rules:
- name: "Inherit code for the page from GitLabDataStreamlitInit"
description: "All Streamlit apps must inherit from GitLabDataStreamlitInit"
severity: "error"
required: true
class_name: "*"
required_base_classes:
- "GitLabDataStreamlitInit"
required_methods:
- "__init__"
- "set_page_layout"
- "setup_ui"
- "run"
function_rules:
- name: "Main function required"
description: "Must have a main() function"
severity: "error"
required: true
function_name: "main"
import_rules:
- name: "Import GitLabDataStreamlitInit"
description: "Must import the mandatory base class"
severity: "error"
required: true
module_name: "gitlab_data_streamlit_init"
required_items:
- "GitLabDataStreamlitInit"
- name: "Import streamlit"
description: "Must import streamlit library"
severity: "error"
required: true
module_name: "streamlit"
file_rules:
- name: "Snowflake configuration required (snowflake.yml)"
description: "Each application must have a snowflake.yml configuration file"
severity: "error"
required: true
file_pattern: "**/applications/**/snowflake.yml"
base_path: ""
- name: "Snowflake environment required (environment.yml)"
description: "Each application must have a environment.yml configuration file"
severity: "error"
required: true
file_pattern: "**/applications/**/environment.yml"
base_path: ""
- name: "Share specification required (share.yml)"
description: "Each application must have a share.yml file"
severity: "warning"
required: true
file_pattern: "**/applications/**/share.yml"
base_path: ""
- name: "README.md required (README.md)"
description: "Each application should have a README.md file with a proper documentation"
severity: "error"
required: true
file_pattern: "**/applications/**/README.md"
base_path: ""
- name: "Starting point recommended (dashboard.py)"
description: "Each application must have a dashboard.py as a starting point"
severity: "warning"
required: true
file_pattern: "**/applications/**/dashboard.py"
base_path: ""
sql_rules:
- name: "SQL files must contain only SELECT statements"
description: "SQL files and SQL code in other files should only contain SELECT statements for data safety"
severity: "error"
required: true
file_extensions: [".sql", ".py"]
select_only: true
forbidden_statements:
- ....
case_sensitive: false
- name: "SQL queries should include proper SELECT statements"
description: "When SQL is present, it should contain proper SELECT statements"
severity: "warning"
required: false
file_extensions: [".sql", ".py"]
required_statements:
- "SELECT"
case_sensitive: false
share_rules:
- name: "Valid functional roles in share.yml"
description: "Share.yml files must contain only valid functional roles from the approved list"
severity: "error"
required: true
file_pattern: "**/applications/**/share.yml"
valid_roles:
- ...
safe_data_roles:
- ...
- name: "Share.yml file format validation"
description: "Share.yml files must follow the correct YAML format structure"
severity: "error"
required: true
file_pattern: "**/applications/**/share.yml"
required_keys:
- "share"
min_roles: 1
max_roles: 10
Mit einem einzigen Kommando:
╰─$ make streamlit-rules
lassen sich alle erstellten Regeln verifizieren und validieren, dass Entwicklungsteams (die eine Streamlit-Anwendung erstellen) die von den Creators (die Policies und Building Blocks des Frameworks festlegen) spezifizierten Richtlinien befolgen und alle Building Blocks an der richtigen Stelle sind. Dies gewährleistet konsistentes Verhalten über alle Streamlit-Anwendungen hinweg.
🔍 Running Streamlit compliance check...
================================================================================
CODE COMPLIANCE REPORT
================================================================================
Generated: 2025-08-18 17:05:12
Files checked: 4
SUMMARY:
✅ Passed: 4
❌ Failed: 0
Success Rate: 100.0%
APPLICATION COMPLIANCE SUMMARY:
📱 Total Applications Checked: 1
⚠️ Applications with Issues: 0
📊 File Compliance Rate: 100.0%
DETAILED RESULTS BY APPLICATION:
================================================================================
✅ PASS APPLICATION: main_app
------------------------------------------------------------
📁 FILES ANALYZED (4):
✅ dashboard.py
📦 Classes: SnowflakeConnectionTester
🔧 Functions: main
📥 Imports: os, pwd, gitlab_data_streamlit_init, snowflake.snowpark.exceptions, streamlit
✅ show_streamlit_apps.py
📦 Classes: ShowStreamlitApps
🔧 Functions: main
📥 Imports: pandas, gitlab_data_streamlit_init, snowflake_session, streamlit
✅ available_packages.py
📦 Classes: AvailablePackages
🔧 Functions: main
📥 Imports: pandas, gitlab_data_streamlit_init, streamlit
✅ share.yml
👥 Share Roles: snowflake_analyst_safe
📄 FILE COMPLIANCE FOR MAIN_APP:
✅ Required files found:
✓ snowflake.yml
✓ environment.yml
✓ share.yml
✓ README.md
✓ dashboard.py
RULES CHECKED:
----------------------------------------
Class Rules (1):
- Inherit code for the page from GitLabDataStreamlitInit (error)
Function Rules (1):
- Main function required (error)
Import Rules (2):
- Import GitLabDataStreamlitInit (error)
- Import streamlit (error)
File Rules (5):
- Snowflake configuration required (snowflake.yml) (error)
- Snowflake environment required (environment.yml) (error)
- Share specification required (share.yml) (warning)
- README.md required (README.md) (error)
- Starting point recommended (dashboard.py) (warning)
SQL Rules (2):
- SQL files must contain only SELECT statements (error)
🗄 SELECT-only mode enabled
🚨 Forbidden: INSERT, UPDATE, DELETE, DROP, ALTER...
- SQL queries should include proper SELECT statements (warning)
Share Rules (2):
- Valid functional roles in share.yml (error)
👥 Valid roles: 15 roles defined
🔒 Safe data roles: 11 roles
- Share.yml file format validation (error)
------------------------------------------------------------
✅ Compliance check passed
-----------------------------------------------------------
Developer Experience
Ob bevorzugte IDE, webbasierte Entwicklungsumgebung oder Snowflake Snowsight – die Experience bleibt konsistent. Das Framework bietet:
- Template-basierte Entwicklung: Neue Anwendungen und Pages werden über standardisierte Templates erstellt, was Konsistenz und Best Practices von Tag eins sicherstellt. Keine verstreuten Designs und Elemente mehr.
╰─$ make streamlit-new-app NAME=sales_dashboard
🔧 Configuration Environment: TEST
📝 Configuration File: config.yml
📜 Config Loader Script: ./setup/get_config.sh
🐍 Python Version: 3.12
📁 Applications Directory: ./src/applications
🗄 Database: ...
📊 Schema: ...
🏗 Stage: ...
🏭 Warehouse: ...
🆕 Creating new Streamlit app: sales_dashboard
Initialized the new project in ./src/applications/sales_dashboard
- Poetry Package Management: Alle Dependencies werden über Poetry verwaltet, was isolierte Umgebungen schafft, die bestehende Python-Setups nicht stören.
[tool.poetry]
name = "GitLab Data Streamlit"
version = "0.1.1"
description = "GitLab Data Team Streamlit project"
authors = ["GitLab Data Team <*****@gitlab.com>"]
readme = "README.md"
[tool.poetry.dependencies]
python = "<3.13,>=3.12"
snowflake-snowpark-python = "==1.32.0"
snowflake-connector-python = {extras = ["development", "pandas", "secure-local-storage"], version = "^3.15.0"}
streamlit = "==1.22.0"
watchdog = "^6.0.0"
types-toml = "^0.10.8.20240310"
pytest = "==7.0.0"
black = "==25.1.0"
importlib-metadata = "==4.13.0"
pyyaml = "==6.0.2"
python-qualiter = "*"
ruff = "^0.1.0"
types-pyyaml = "^6.0.12.20250516"
jinja2 = "==3.1.6"
[build-system]
requires = ["poetry-core"]
build-backend = "poetry.core.masonry.api"
- Multi-Page-Application-Support: Teams können problemlos komplexe Anwendungen mit mehreren Pages erstellen und neue Libraries nach Bedarf hinzufügen. Multi-Page-Anwendungen sind Teil des Frameworks – Fokus liegt auf der Logik, nicht auf Design und Strukturierung.
<p></p>
<center><i>Multi-Page-Anwendungsbeispiel (in Snowflake)</i></center>
<p></p>
- Nahtlose Snowflake-Integration: Integrierte Konnektoren und Authentication-Handling für sicheren Datenzugriff bieten dieselbe Experience in lokaler Entwicklung und direkt in Snowflake.
make streamlit-push-test APPLICATION_NAME=sales_dashboard
📤 Deploying Streamlit app to test environment: sales_dashboard
...
------------------------------------------------------------------------------------------------------------
🔗 Running share command for application: sales_dashboard
Running commands to grant shares
🚀 Executing: snow streamlit share sales_dashboard with SOME_NICE_ROLE
✅ Command executed successfully
📊 Execution Summary: 1/1 commands succeeded
-
Umfassendes Makefile: Alle gängigen Kommandos sind in einfache Makefile-Befehle verpackt, von lokaler Entwicklung über Testing bis Deployment, inklusive CI/CD-Pipelines.
-
Sichere lokale Entwicklung: Alles läuft in isolierten Poetry-Umgebungen, schützt das System und bietet Production-ähnliche Experiences.
<p></p>
<center><i>Konsistente Experience unabhängig von der Umgebung (Beispiel lokale Entwicklung)</i></center>
<p></p>
- Collaboration via Code: Alle Anwendungen und Komponenten sind in einem Repository zusammengefasst, was der gesamten Organisation ermöglicht, an denselben Ressourcen zu kollaborieren und doppelte Arbeit sowie redundante Setups zu vermeiden.
Implementierungsschritte
Bei ähnlichen Herausforderungen mit verstreuten Streamlit-Anwendungen:
-
Bestandsaufnahme: Bestehende Anwendungen inventarisieren und Problembereiche identifizieren.
-
Rollen definieren: Maintainer-Verantwortlichkeiten von Creator- und Endnutzer-Anforderungen trennen.
-
Mit Templates beginnen: Standardisierte Anwendungs-Templates erstellen, die Security- und Compliance-Anforderungen durchsetzen.
-
CI/CD implementieren: Deployment-Pipeline automatisieren, um manuelle Fehler zu reduzieren und Konsistenz sicherzustellen.
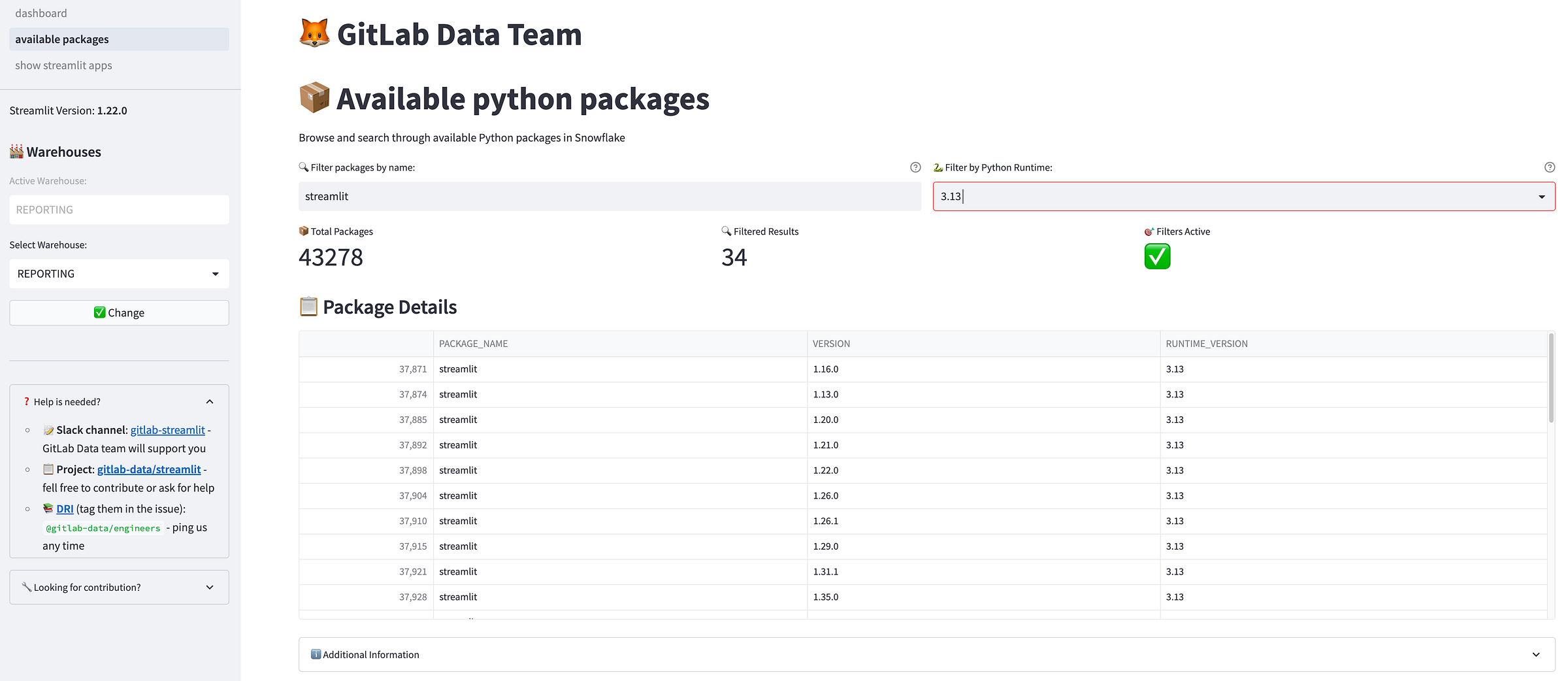
<p></p>
<center><i>Die in Snowflake deployte Anwendung</i></center>
Einordnung
Dieses Framework behandelt Daten-Anwendungen als vollwertige Komponenten der Enterprise-Architektur.
Durch die Bereitstellung von Struktur ohne Flexibilitätsverlust hat das GitLab Data Team eine Umgebung geschaffen, in der Teams mit minimalen technischen Vorkenntnissen schnell innovieren können, während höchste Security- und Compliance-Standards gewahrt bleiben.
Ausblick
Wir entwickeln das Framework basierend auf User-Feedback und entstehenden Anforderungen kontinuierlich weiter. Zukünftige Verbesserungen umfassen erweiterte Template-Libraries, verbesserte Monitoring-Funktionen, mehr Flexibilität und eine optimierte User Experience.
Das Ziel: ein Foundation schaffen, das mit den wachsenden Data-Application-Anforderungen der Organisation skaliert.
Weitere technische Details zur Implementierung im englischen Original.
Zusammenfassung
Das GitLab Data Team hat dutzende verstreute, unsichere Streamlit-Anwendungen ohne Standardisierung in ein einheitliches, Enterprise-taugliches Framework mit klarer Rollentrennung überführt:
-
Maintainers verwalten Infrastruktur und Security.
-
Creators konzentrieren sich auf Anwendungsentwicklung ohne Deployment-Overhead.
-
Viewers greifen auf fertige, compliance-konforme Apps zu.
Die verwendeten Building Blocks:
-
Automatisierte CI/CD-Pipelines
-
Vollständig kollaborativer und versionierter Code in git
-
Template-basierte Entwicklung
-
Integrierte Security-Compliance und Testing
-
Poetry-verwaltete Umgebungen
Wir haben den Wartungs-Overhead eliminiert und gleichzeitig schnelle Innovation ermöglicht – der Beweis, dass Struktur und Flexibilität vereinbar sind, wenn Data Applications als vollwertige Enterprise-Assets behandelt werden, nicht als Wegwerf-Prototypen.
]]>


 {altText="Screenshot showing the model selection dropdown in GitLab Duo with Claude Sonnet 4.5 highlighted as an available option"}
{altText="Screenshot showing the model selection dropdown in GitLab Duo with Claude Sonnet 4.5 highlighted as an available option"}